TOC
本文从一个业务连接异常切入,分析了在高并发短连接场景下,TCP协议TIME_WAIT状态导致端口资源耗尽的问题。结合故障案例,介绍了TIME_WAIT的原理、常见误区、实验复现过程,并给出了内核参数调整和应用层优化的解决思路。
1. 故障分析
最近公司某微服务集群中的一个HTTP服务突然出现大量连接失败,业务方反馈接口频繁超时,部分请求直接报错:
java.net.BindException: Address already in use: connect
进一步排查,发现该服务为高并发短连接场景(未启用HTTP Keep-Alive),每秒新建和关闭大量TCP连接。通过 ss -ano | grep TIME-WAIT | wc -l 统计,TIME_WAIT状态的连接数高达两万余个,远超正常水平。这是典型的由于本地端口被TIME_WAIT占用,新建连接频繁失败,导致业务异常的场景。
TIME_WAIT是TCP四次挥手关闭连接过程中,主动关闭方进入的一个状态。在这个状态下的连接依然占据端口,过多的TIME_WAIT状态连接会导致本地端口资源耗尽,影响新连接的建立。大多数情况下,我们使用的都是长连接,没有遇到过这种问题,趁这个案例便一起来分析下。
2. TIME_WAIT状态介绍
众所周知,TCP是面向连接的协议,建立连接和关闭连接都需要经过一系列协商过程。
建立一个连接需要3次握手,而终止一个连接要经过4次挥手。这由TCP的半关闭(half-close)造成。既然一个TCP连接是全双工(即数据在两个方向上能同时传递),因此每个方向必须单独地进行关闭。这原则就是当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向连接。 – 《TCP/IP详解-卷1: 18.2.4 连接终止协议》
具体来说,TCP面向连接意味着通信双方通过4元组(源IP地址/源端口号/目标IP地址/目标端口号/协议类型TCP)来标示一个连接。由于端口资源的有限性和可回收性,在确认连接不再使用后,应该有一个合理的机制来释放端口资源。故而便有了在断连过程中针对两次FIN的两次ACK过程。
两次ACK完成之后,主动发起关闭连接的一方便可以释放端口资源了。但不是马上释放,而是进入TIME_WAIT状态,等待一段时间后(默认持续2*MSL,Maximum Segment Lifetime,报文最大生存时间,默认2分钟)再彻底关闭连接。
下图是完整的4次挥手过程:
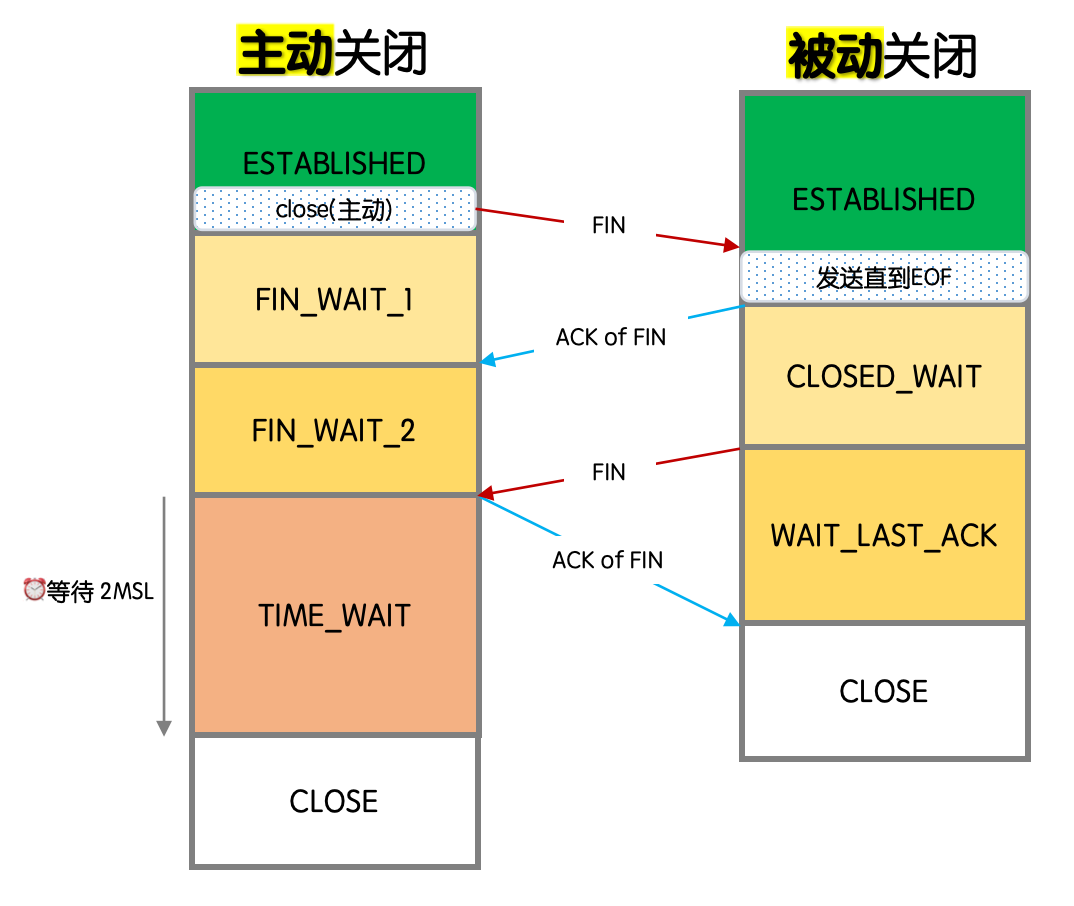
现在我们知道了TIME_WAIT状态导致端口资源被占用的原因。但是为什么要有TIME_WAIT状态呢?这主要是为了保证连接的可靠性和数据完整性。在TCP连接关闭后,可能会有一些延迟的数据包仍然在网络中传输。如果没有TIME_WAIT状态,这些延迟的数据包可能会被错误地当作新的连接请求处理,从而导致数据混乱或丢失。TIME_WAIT状态可以确保在连接关闭后的一段时间内,所有延迟的数据包都被处理完毕,从而避免这种问题。
TIME_WAIT存在的另一个重要原因是保证“被动关闭连接”的一方能够被正确关闭。在TCP四次挥手过程中,主动关闭方发送的最后一个对被动方FIN的ACK报文(图中第二个ACK of FIN)有可能丢失。如果被动方没有收到ACK,会重发FIN报文。如果此时主动方已经进入CLOSE状态,收到FIN后会响应RST报文而不是ACK,这会导致被动方无法正常关闭连接。因此,主动方需要在TIME_WAIT状态等待一段时间,确保被动方能够收到ACK并正常关闭连接。
原理讲解到此为止,下面我们通过几个小实验来观察TIME_WAIT状态的实际表现。
3. 故障重现
实验环境:Server(服务端,ubuntu)和Client(客户端,ubuntu)。
3.1 尝试一:http.server + ab工具
简单的短连接HTTP服务,首先想到的是使用Python内置HTTP服务器——刚好是短链接服务,结合Apache Benchmark工具(ab)发起大量短连接请求:
# 在 Server 节点启动 HTTP 服务(监听 8080 端口)
server# python3 -m http.server 8080
# 在 Client 节点模拟大量短连接请求
client# ab -n 100000 -c 100 http://<server-ip>:8080/
在施压过程中观察到:
# 在Client节点上没有任何TIME_WAIT状态的
client# netstat -anp |grep 8080|grep TIME_WAIT|wc -l
0
# 在Server节点上观察到大量TIME_WAIT状态的连接
server# netstat -anp |grep 8080 |grep TIME_WAIT|wc -l
27448
压测结束,没有报错。有两个意外的现象:
- client端没有观察到TIME_WAIT连接,这跟故障中客户端TIME_WAIT导致耗尽端口的现象不一致。
- server端观察到了大量的TIME_WAIT连接,但却平稳运行没有出现任何崩溃。
对照TCP四次挥手的流程图,注意到加粗标记存在TIME_WAIT状态的是主动关闭的一方。很多文章将其标记为客户端,实际上并不完全准确。TCP是面向连接的协议,任何一方都可以主动发起关闭连接的请求。因此主动关闭连接的一方可以是客户端,也可以是服务端。在实际应用中,通常是客户端主动发起关闭连接请求(如浏览器关闭页面、telnet客户端键入quit退出),因此习惯性地将主动关闭方称为客户端。但是更准确的说法是“主动关闭连接的一方”,而不是简单地称为客户端。
而在我们这个压测场景中,恰恰就不是常见的场景。server端是一个文件服务器,在完成文件传输之后会主动关闭连接,而不是由客户端来断连。于是TIME_WAIT状态会出现在服务端这一边。
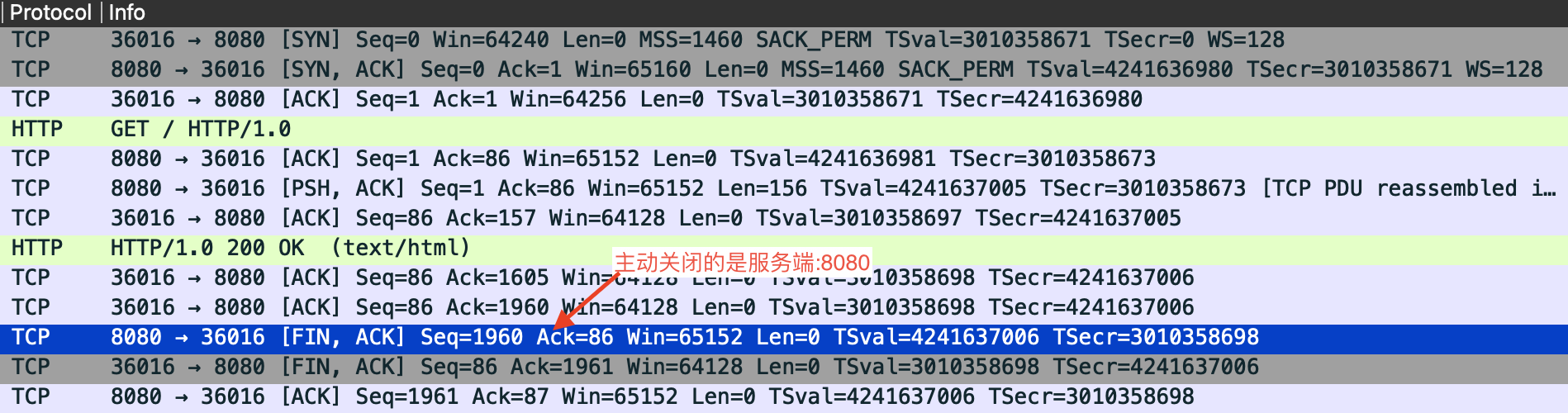
另外客户端和服务端TIME_WAIT过多,造成的影响是不同的。
如果客户端的TIME_WAIT状态过多,占满了所有端口资源,会导致无法发起新的TCP请求,也就是文首提到的Address already in use异常。严格来说只是指向同一个目标ip+port的服务器的TCP连接无法建立,更细节可以看这篇文章有详细的介绍。
如果服务端的TIME_WAIT状态过多,并不会导致端口资源受限,因为服务端只监听一个端口,理论上服务端可以建立很多连接,但是TCP连接过多,会占用系统资源,比如文件描述符、内存资源、CPU资源等。
在我们这个压测场景中,并没有导致服务端产生多少资源压力,所以请求都是成功的。
3.2 尝试二:nginx + ab工具
为了重现服务端主动发起断连的场景,我将python的http.server服务替换为nginx,后者默认并不会主动关闭连接。而客户端沿用ab,它在完成一次请求之后会主动关闭。
# 在 Server 节点启动nginx服务,过程忽略
server# ...
# 在 Client 节点模拟大量短连接请求
client# ab -n 100000 -c 100 http://<server-ip>:8080/
通过抓包也能看到是客户端在完成数据接收之后主动发起了断连操作:
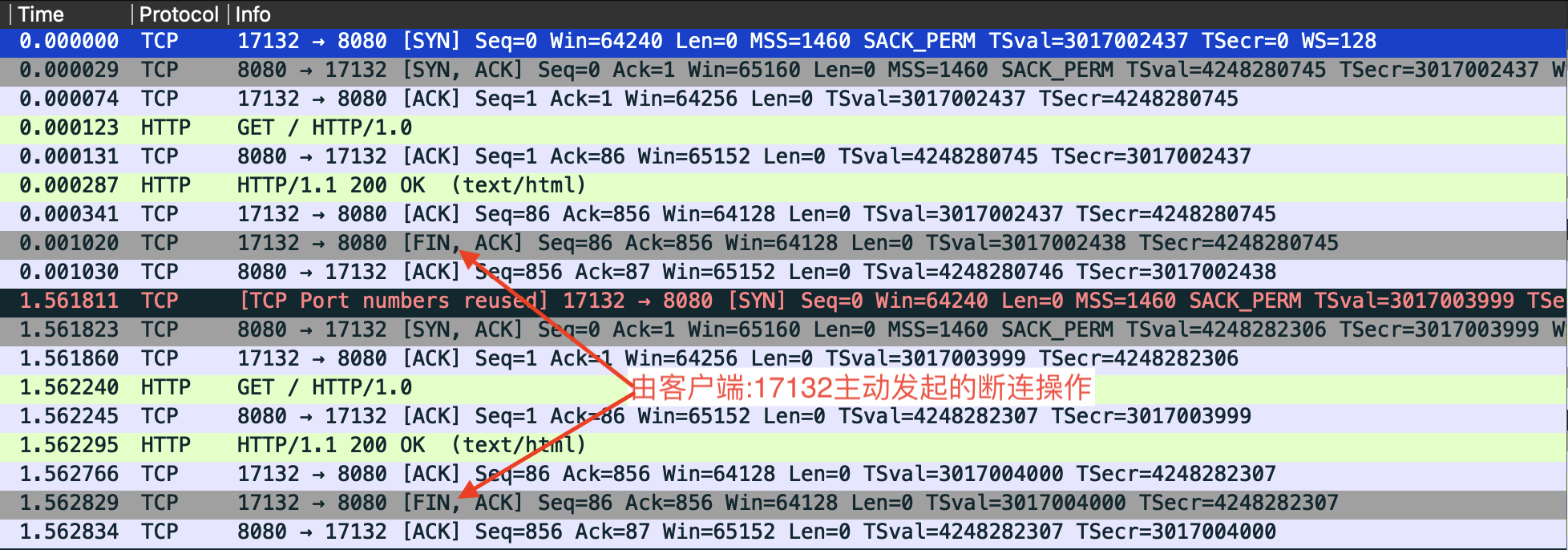
但是观察节点连接状态,仍有不解的地方:
- TIME_WAIT状态的连接依然大量出现在server端,而不是主动关闭连接的client端。
# 在Server节点上观察到大量TIME_WAIT状态的连接 server# netstat -anp |grep 8080 |grep TIME_WAIT|wc -l 27462
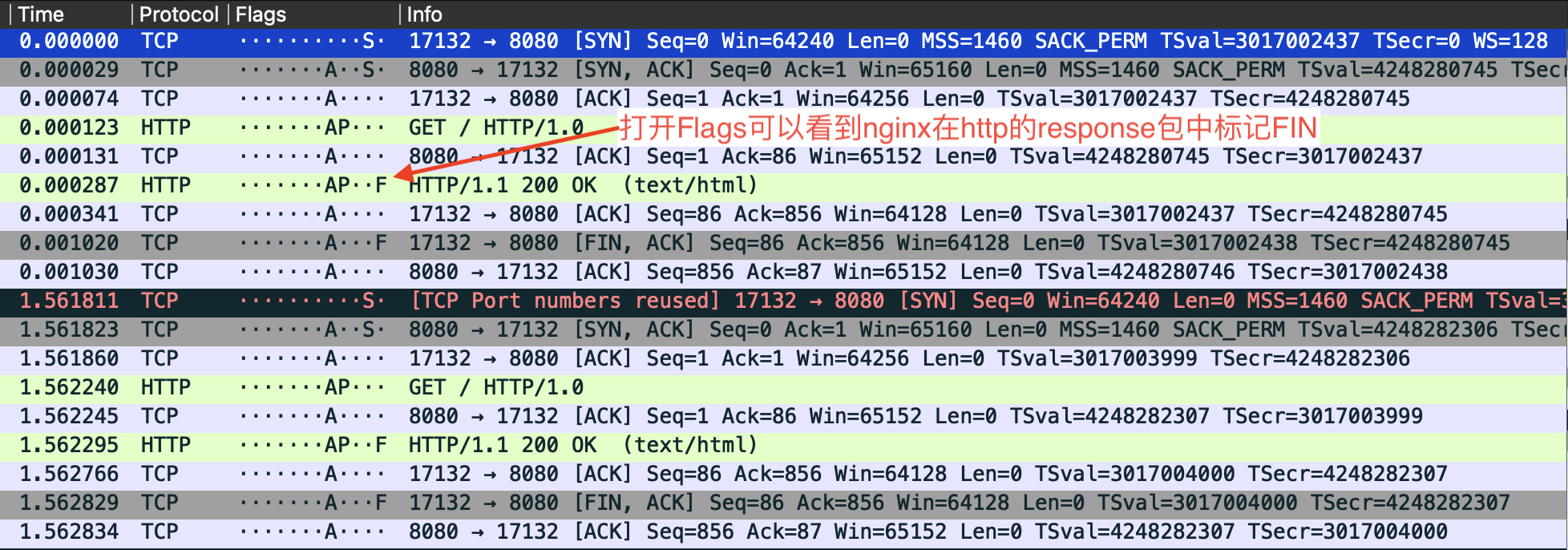
这个问题原来是一场误会。事实上Nginx和python的http.server一样,在处理短链接的时候,会在完成响应之后主动关闭连接。区别在于python http.server把FIN放在一个独立的tcp包中,而Nginx将FIN跟http的response放在同一个tcp包中。由于wireshark抓包会自动识别HTTP协议包,则展示为http的形式。所以造成了第一个FIN是由客户端发起的错觉。
3.3 尝试三:手动编写server
既然现成的http服务器没法实现,下面用Python socket来编写最简单的server和client,演示“客户端先于服务端主动关闭连接”场景:
server.py
import socket
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(('0.0.0.0', 8080))
server.listen(5)
print('Server listening on 8080...')
while True:
conn, addr = server.accept()
try:
# 尝试接受数据, 但client实际上不会发送, 而是优先关闭连接
data = conn.recv(1024)
except Exception as e:
print('Error:', e)
conn.close()
client.py
import socket
import time
for i in range(10):
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(('{serverIP}', 8080))
# 客户端主动关闭连接,不等待服务端响应
s.close()
# 调整sleep控制TPS
time.sleep(0.5)
基于watch观察netstat
watch -n 1 "netstat -ant | awk '\$4 ~ /:8080$/ || \$5 ~ /:8080$/ {states[\$6]++} END {for (s in states) print s, states[s]}'"
这次终于可以观察到TIME_WAIT状态的连接出现在客户端了。然后通过调整client.py中的sleep时间来控制TPS,观察到随着TPS的增加,客户端的TIME_WAIT状态连接数也会迅速增加。增加到一定程度后,客户端开始出现OSError: [Errno 99] Cannot assign requested address异常,表示本地端口资源耗尽。
4. 问题解决
终于重现了故障场景。原因知道了,解决方案其实相对简单。
4.1 内核参数调整
在定位到TIME_WAIT导致端口耗尽后,首先可以考虑通过调整内核参数来缓解问题。虽然这些参数不能从根本上消除TIME_WAIT,但可以在一定程度上延缓或减轻端口耗尽的风险。
net.ipv4.ip_local_port_range: 定义本地端口的范围,默认是32768到60999。在高并发短连接场景下,可以扩大本地端口范围,增加可用端口数量。但是这并不能解决TIME_WAIT导致的端口耗尽问题,因为TIME_WAIT状态的连接仍然会占用端口。net.ipv4.tcp_fin_timeout: 定义TIME_WAIT状态的持续时间,默认是60秒。在客户端缩短TIME_WAIT持续时间可以减少端口占用。但高吞吐的情况下,治标不治本。net.ipv4.tcp_tw_reuse: 允许处于TIME_WAIT状态的socket被新连接复用,默认是2(0: 禁用;1: 启用;2: 仅对loopback连接启用)。在高并发短连接的服务端,开启tcp_tw_reuse可以一定程度上缓解端口耗尽,但根本解决还需配合应用层优化(如Keep-Alive、连接池)和架构调整。
在上述的python socket实验中,通过将tcp_tw_reuse设置为1,可以观察到客户端的TIME_WAIT连接数不会超过ip_local_port_range的范围,避免了端口耗尽的问题。
如何修改内核参数? 可以通过
sysctl命令临时修改内核参数,例如:sudo sysctl -w net.ipv4.tcp_tw_reuse=1 sudo sysctl -w net.ipv4.tcp_fin_timeout=30 sudo sysctl -w net.ipv4.ip_local_port_range="1024 65535"查看当前参数值:
sysctl net.ipv4.tcp_tw_reuse sysctl net.ipv4.tcp_fin_timeout sysctl net.ipv4.ip_local_port_range若需永久生效,可将参数写入
/etc/sysctl.conf,然后执行sudo sysctl -p使其生效。
4.2 应用层&架构优化
调整内核参数,尤其是tcp_tw_reuse,可以在一定程度上缓解端口耗尽问题,但从根本上解决还是需要从应用层和架构上进行设计优化。比如:
- 启用HTTP Keep-Alive,避免短链接频繁创建。
- 有的场景下短链接对于服务端来说是必要的,只能通过客户端的错误容忍来处理。比如捕获
OSError: [Errno 99] Cannot assign requested address异常,等待一段时间后重试。
5. 总结
TIME_WAIT状态是TCP协议为保证连接可靠性和数据完整性而设计的机制,但在高并发短连接场景下,容易导致端口资源耗尽,影响新连接的建立。通过合理调整内核参数(如扩大端口范围、缩短TIME_WAIT持续时间、开启端口复用)可以缓解问题,但根本的解决方案还需从应用层入手,比如启用长连接、连接池等方式减少短连接的创建。遇到端口耗尽问题时,建议结合系统参数和业务架构双管齐下,综合优化。